Daten-Tiering-Optimierung durch Native Storage Extension mit SAP BW/4HANA 2.0

Dieser Blog soll einige praktische Anleitungen und Ratschläge für die Implementierung von Data Tiering Optimisation (DTO) mit Native Storage Extension (NSE) auf SAP BW/4HANA 2.0-Systemen mit dynamischem Data Tiering geben.
NSE ist für Native HANA-Lösungen ab SAP HANA 2.0 SP04 verfügbar. Seit SP05 ist dies nun auch für die SAP BW/4HANA-Anwendung verfügbar (es ist immer noch relevant, wenn Sie die HANA-Datenbank nativ für Nicht-SAP-Daten verwenden, aber wir werden diesen Aspekt in diesem Blog nicht behandeln).
Was ist Data Tiering?
Data Tiering ist ein Prozess, mit dem Sie Daten verschiedenen Speicherbereichen und Speichermedien zuordnen können. Die Kriterien für diese Entscheidung können Datentyp, betriebliche Erwägungen, Leistungsanforderungen, Zugriffshäufigkeit und Sicherheitsanforderungen sein. Die nachstehenden Definitionen geben einen Anhaltspunkt dafür, was als heisse, warme oder kalte Daten betrachtet werden kann.

Was ist NSE?
NSE ist eine alternative Speicherverwaltungslösung für warme Daten, während wir in der Vergangenheit möglicherweise Scale-out Extension Nodes verwendet haben. Jetzt haben wir die Möglichkeit, je nach verfügbarer Architektur eine dieser beiden Lösungen zu verwenden.
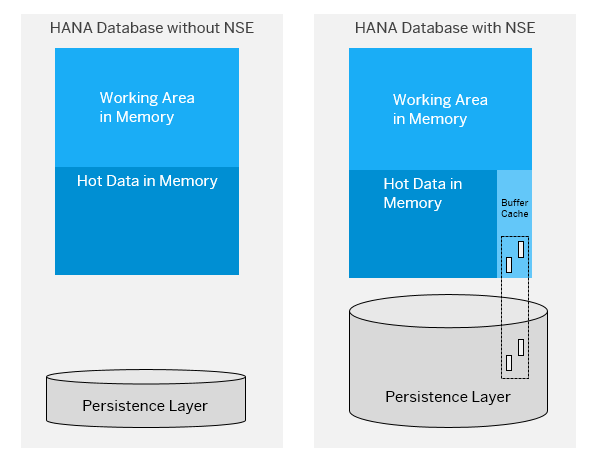
Wie die Beschreibung schon sagt, verwendet NSE Native Storage zur Verwaltung der Daten. Daten, die als «warm» eingestuft werden (in meinem Beispiel mit DTO), werden auf der Festplatte als «page loadable» persistiert, und wenn diese speziellen Daten gelesen werden, werden sie in den Puffer verschoben, der NSE zugewiesen ist. Die Standardgrösse des NSE-Speichers beträgt 10 % des Gesamtspeichers, obwohl dieser reserviert und nicht zugewiesen ist. SAP HANA hat Zugriff auf 100 % des verfügbaren Speichers, wenn Sie NSE nicht verwenden. Da die Daten von der Festplatte gelesen werden, sollte sorgfältig überlegt werden, welche Daten im warmen Speicher persistiert werden sollen.
Ganze Tabellen, Partitionen oder nur Spalten können in den NSE verschoben werden, um den für die HANA-Datenbank benötigten Gesamtspeicherplatz zu reduzieren. In dem Beispiel in diesem Blog werden wir Partitionen verschieben.
Das folgende Diagramm zeigt die HANA-Datenbank mit und ohne NSE-Konfiguration.
Weitere Informationen zu NSE finden Sie unter SAP HANA Hilfe
Welche Daten und wie sollten wir DTO implementieren?
Daten in BW/4HANA können sowohl nativ als auch in einem verwalteten Schema sein. In diesem Blog befassen wir uns speziell mit Daten in benutzerdefinierten Tabellen im verwalteten Schema, genauer gesagt mit Daten, die in unseren benutzerdefinierten aDSOs aufgefüllt werden (obwohl NSE auf alle Daten anwendbar ist, ob sie nativ oder verwaltet sind, einschliesslich Systemtabellen).
Wenn Sie Einblicke in SAP HANA erhalten möchten, was für NSE in Frage kommt, können Sie den NSE Advisor einschalten. Die Ergebnisse können mit dem SQL-Editor im DBA-Cockpit (Transaktion DB02) abgefragt werden oder Sie können das SAP HANA Cockpit verwenden.
Bei der Implementierung von DTO haben wir zwei Dinge berücksichtigt: Erstens, wie gross eine Tabelle (Anzahl der Zeilen) sein muss, damit sie für NSE in Frage kommt, und zweitens, wie die Temperatur aufrechterhalten werden soll.
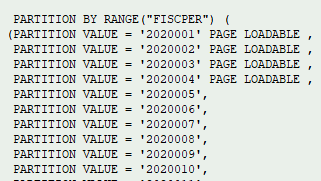
Unser Leitgedanke war, dass der Kunde ältere Daten dynamisch in den warmen Speicher verschieben wollte, also entschieden wir uns, die Temperatur auf Partitionsebene zu regeln. Das InfoObject wäre 0FISCPER, da es in den BW-Queries stark genutzt wurde. Eine Partitionierung auf dieser Ebene würde uns die beste Lösung für unsere DTO-Kriterien bieten und gleichzeitig sicherstellen, dass die Partitionen die in den BW-Queries geltenden Einschränkungen widerspiegeln.
Bei der Definition eines aDSO für die Partitionierung sind einige wichtige Dinge zu beachten
- SAP HANA kann nur maximal 16’000 Partitionen haben. Sie müssen also genau auf die Daten achten, die Sie für die Erstellung von Partitionen verwenden, damit Sie nicht an die Grenzen stossen.
- Das Objekt, das Sie partitionieren, muss ein unveränderliches sein, da es in den aDSO-Schlüssel aufgenommen werden muss. Wenn Sie einen Data Mart vom Typ aDSO verwenden, ist es standardmässig im Schlüssel enthalten.
- Wenn Sie 0FISC* InfoObject als Partitionsschlüssel verwenden, müssen Sie auch 0FISCVARNT in den Schlüssel aufnehmen und eine Konstante für die aDSO definieren, um die Partitionierung zu ermöglichen.
In drei einfachen Schritten können Sie Ihr aDSO für Dynamic Data Tiering aktivieren.
1 – Stellen Sie die Warmdatenspeicherung ein und wählen Sie die Temperaturerhaltung.

2 – Fügen Sie die relevanten Objekte zum Tabellenschlüssel für eine Standard-DSO hinzu und geben Sie die Einschränkungskriterien für 0FISCVARNT ein, wenn Sie eine 0FISC*-InfoObject-Partitionierung verwenden.
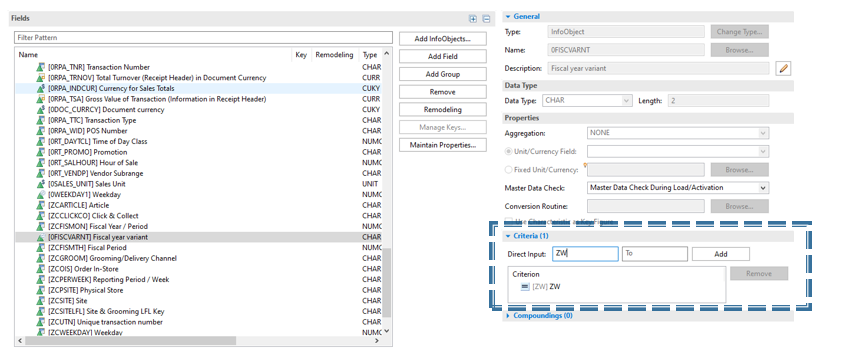
3 – Nachdem das aDSO mit den entsprechenden Einstellungen eingerichtet wurde, können Sie auf der Registerkarte aDSO-Einstellungen Felder für Partitionen definieren.

An diesem Punkt ist der aDSO nun für das dynamische Data Tiering eingerichtet, aber Sie müssen die Regel für die Temperaturpflege festlegen, was mit der standardmässigen Fiori-Kachel oder RSA1 in der BW-Gui erreicht werden kann. Wir finden, dass die Verwendung der Fiori-Kachel Vorteile gegenüber der Gui hatte, da man dieselbe Regel für mehrere aDSOs mit ein paar Klicks erstellen konnte, so dass man sie nicht wiederholen musste. Bei der Ausführung der DTO-Regel fanden wir jedoch, dass die Benutzeroberfläche schneller reagierte, da wir in Fiori beim Versuch, die Regeln auszuführen, eine gewisse Latenz erlebten.
1 – Erstellen Sie die Regel (für einen oder mehrere aDSO’s)
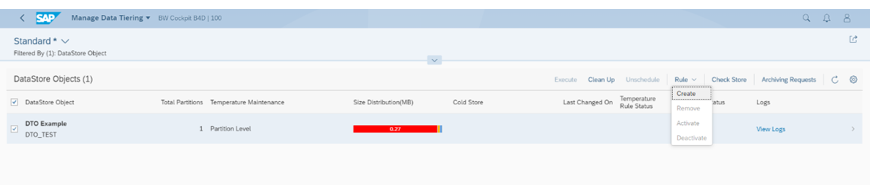
2 – Wählen Sie den Zeitraum und die Aktion. Hier können Sie die Partition ins Warme verschieben und/oder löschen. Sie können auch mehrere Schritte für die Regel festlegen (es ist zu beachten, dass Sie Daten nicht direkt von «Heiss» nach «Kalt» verschieben können, sondern als Zwischenschritt nach «Warm» gehen müssen).
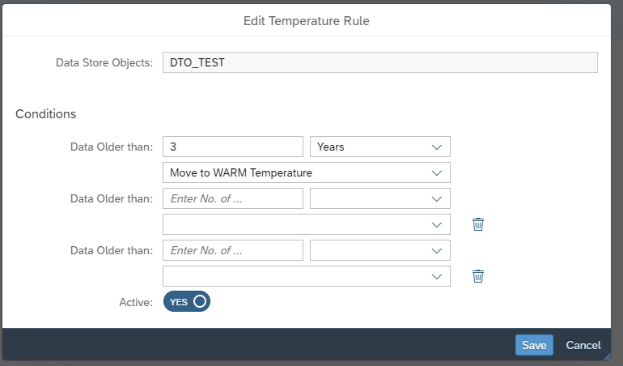
N.B.Die Definition der Regel ist mandantenspezifisch und kann nicht durch die Systemlandschaft transportiert werden. Alle anderen Aspekte im Zusammenhang mit DTO sollten transportiert werden.
Das System ist nun bereit, die DTO-Regel auszuführen, und wie immer kann dies auf eine von mehreren Arten geschehen.
- Innerhalb der Fiori-Kachel «Manage Data Tiering
- DTO-Ausführung im Verwaltungsbereich in RSA1
- Verwendung des Schritts Adjust Data Tiering in einer Prozesskette
Wir empfehlen natürlich die Einrichtung der Prozesskette, die auch ohne Vorhandensein einer Regel erstellt werden kann.
Ein wichtiger Punkt ist, dass Sie, wenn Sie DTOs auf Data Marts vom Typ aDSOs ausführen, eine Bereinigungsaktion vom Typ ‹Activate Requests› durchführen müssen (‹Compress› für die erfahreneren BW-Berater!), bevor die Partitionen für die Temperaturpflege in Betracht gezogen werden.
Schlussfolgerungen
Unser System wurde mit ~5 Jahren an Daten initialisiert, und wir hatten eine Reihe unserer aDSOs für DTO konfiguriert. Jede hatte eine Regel, um alles, was älter als 30 Monate war, in den warmen Speicher zu verschieben.
Nach einer erfolgreichen DTO-Ausführung konnten wir sehen, dass die betreffenden Partitionen gemäss den Temperaturregeldefinitionen in den warmen Speicher verschoben worden waren, und wir konnten auch die Grösse des Speichers im warmen Speicher sehen.

Die Fiori-Kachel bietet jedoch ein anderes Bild – wir glauben jedoch nicht, dass diese Ansicht zutreffend ist, daher ist sie mit Vorsicht zu geniessen.

Wir konnten im DBA-Cockpit sehen, dass die Partitionen als auslagerungsfähig markiert und auf der Festplatte gespeichert sind.
Nachdem wir den DTO-Job für alle unsere aDSOs ausgeführt hatten, konnten wir die Ergebnisse (siehe unten) der gesamten Daten, die vom heissen in den warmen Speicher verschoben worden waren, mithilfe der Standard-Fiori-Kachel «Data Volume Statistics» sehen.
Fast die Hälfte der Daten, die sich im Hot-Storage befanden, was in diesem Fall ca. 30 % der gesamten Speichernutzung ausmachte, wurde vom Hot-Storage in den Warm-Storage verschoben, wodurch mehr als 400 GB Speicher freigesetzt wurden – insgesamt ein beeindruckendes Ergebnis. Die Reduzierung der Speichernutzung macht das System zukunftssicher für ein erhebliches organisches Wachstum oder zusätzliche Berichtsdatensätze.
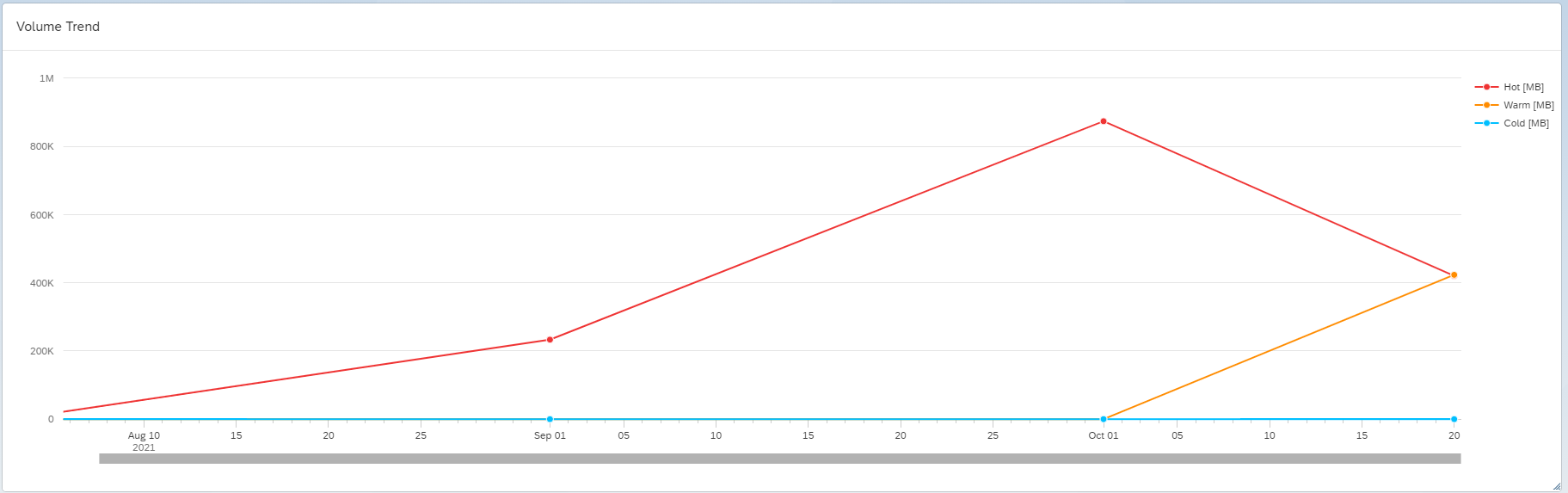
Die Auswirkungen auf das Wachstum des belegten Speicherplatzes waren vernachlässigbar, wenn nicht sogar spürbar.
Wir führten eine Reihe von Abfragen aus, um die Abfrageleistung zu bewerten. Die verwendeten Abfragen hatten eine einzige Auswahl auf 0FISCPER, so dass wir wussten, dass sie auf eine ladbare Partition treffen würden. Die Zusammensetzung der Abfrage selbst bestand jedoch aus mehreren berechneten Kennzahlen und eingeschränkten Kennzahlen, so dass der Datenmanager noch Arbeit zu leisten hatte.
Wir führten zwei Ausführungen (verschiedene Geschäftsjahre/Perioden) einer Abfrage durch, bei der sich die Daten im heissen Speicher befanden, und zwei weitere Ausführungen (wiederum verschiedene Geschäftsjahre/Perioden) derselben Abfrage, bei der sich die Daten im warmen Speicher befanden.
Der Unterschied zwischen der Speicherung der Daten im warmen und im heissen Speicher war geringfügig (0,6 % langsamer).
Ein zweiter Test mit einer komplexeren Abfrage ergab ähnliche Ergebnisse: Hier wurde ein weiterer Test durchgeführt, bei dem die Abfrage mit demselben Geschäftsjahr/Periode zweimal für die Daten im warmen Speicher ausgeführt wurde. Damit war bewiesen, dass die Daten aus dem Speicher-Cache gelesen wurden. Das soll nicht heissen, dass wir bei allen Abfragen die gleiche Leistung erzielen, aber wir waren von den ersten Ergebnissen sehr beeindruckt und werden die Verwendung von NSE bei zukünftigen Projekten weiterhin befürworten.
Alle Fiori-Kacheln, auf die in diesem Blog Bezug genommen wird, sind über das BW4 Web Cockpit verfügbar.
Wenn Sie daran interessiert sind, mehr zu erfahren, oder diese technischen Inhalte im Detail besprechen möchten, nehmen Sie bitte Kontakt mit uns auf