Data Tiering Optimisation using Native Storage Extension with SAP BW/4HANA 2.0

Author – Jonathan Haigh , Senior Analytics Consultant, NTT DATA Business Solutions UK&I
This blog is aimed at providing some practical guidance and advice on implementing Data Tiering Optimisation (DTO) using Native Storage Extension (NSE) on SAP BW/4HANA 2.0 systems using dynamic data tiering.
NSE has been available for Native HANA solutions from SAP HANA 2.0 SP04. This has now been added to the SAP BW/4HANA application since SP05 (it’s still relevant if you’re using the HANA database natively for non-SAP data but we will not be covering that aspect in this blog).
What is Data Tiering?
Data Tiering is a process that allows you to assign data to various storage areas and storage media. The criteria for this decision could be data type, operational considerations, performance requirements, frequency of access, and security requirements. The definitions below provide some guidance on what could be considered as hot, warm or cold data.

What is NSE?
NSE is an alternative storage management solution for warm data, whereas historically we might have used Scale-out Extension Nodes. Now we have the option of using either of these solutions depending on the architecture available.
As the description suggests NSE uses Native Storage to manage the data. Data categorised as being warm (in my example using DTO) will be persisted on disk as page loadable, and when this particular data is read it will move it into the buffer that is allocated to NSE. The default size of the NSE storage is 10% of the overall memory though this is reserved and not allocated. SAP HANA has access to 100% of the available memory if you are not using NSE. Since it’s reading from disk, careful consideration should be taken when determining what data should be persisted in warm storage.
Entire tables, partitions or just columns can be moved into NSE to reduce the overall memory footprint needed for the HANA database. In the example in this blog we will be moving partitions.
The diagram below illustrates the HANA database with and without NSE configured.
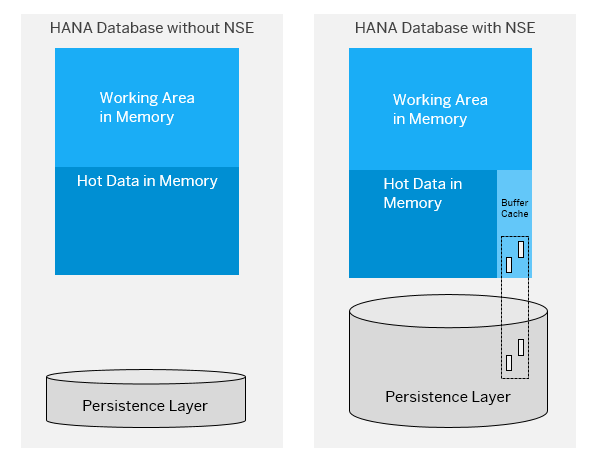
Further information on NSE can be found at SAP HANA Help
What Data and How Should We Implement DTO?
Data in BW/4HANA can be both native or in a managed schema. In this blog we are dealing specifically with data in custom tables in the managed schema, more specifically data populated in our custom aDSO’s (though NSE can be applicable to all data be it native or managed including system tables).
If you are wanting to gain some insights from SAP HANA as to what may be considered for NSE then you are able to switch on the NSE Advisor, the results for this can be queried using the SQL Editor in the DBA Cockpit (Transaction DB02) or you can use the SAP HANA Cockpit.
In order to implement DTO we considered two things, the first being how big a table (number of rows) is before we should consider it for NSE, and secondly, how the temperature would be maintained.
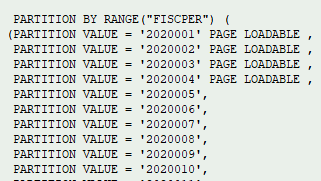
Our guiding principle was that the customer wanted to dynamically move older data into warm storage so we decided on using the partition level to govern the temperature. The InfoObject would be 0FISCPER as this was heavily used in the BW Queries, therefore partitioning on this would provide us with the best solution for our DTO criteria whilst also ensuring the partitions reflect the restrictions being applied in the BW Queries.
There are a few key things you need to be aware of when defining an aDSO for partitioning
- SAP HANA can only have a maximum of 16000 partitions so you need to be acutely aware of the data you are using to create partitions, so you are not reaching the limits.
- The object you are partitioning must be an immutable one as it needs to go into the aDSO key. If you are using a Data Mart type aDSO then it is in the key by default.
- If you are using 0FISC* InfoObject as the partition key then you must also include 0FISCVARNT in the key and define a constant for the aDSO to enable the partitioning.
In three simple steps you can enable your aDSO for Dynamic Data Tiering.
1 – Adjust the warm data storage and select the temperature maintenance.

2 – Add the relevant objects to the table key for a standard aDSO and enter the restriction criteria for 0FISCVARNT if you’re using a 0FISC* InfoObject partitioning.
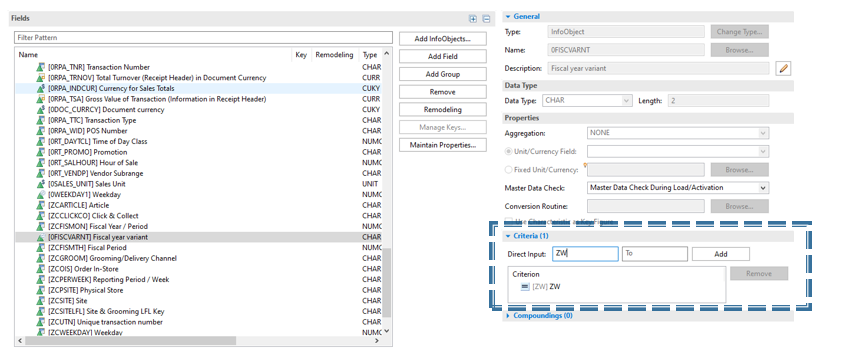
3 – After the aDSO has been setup with the relevant settings you are then able to define field for partitions on the aDSO settings tab.

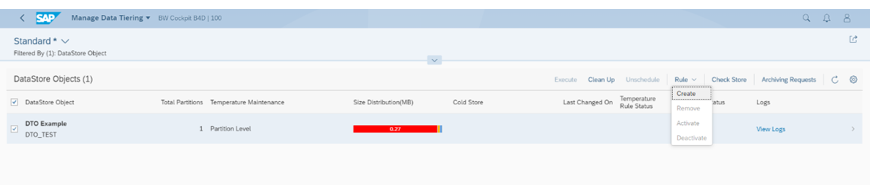
At this point the aDSO is now setup for dynamic data tiering but you need to set the rule for temperature maintenance, which can be achieved using the standard Fiori Tile or RSA1 in the BW Gui. Personally, I found that using the Fiori Tile had advantages over the Gui as you could create the same rule across multiple aDSO’s with a few clicks so you didn’t have to repeat them. However, to execute the DTO rule I found that the Gui was more responsive, as I did experience some latency in Fiori when trying to execute the rules.
1 – Create the rule (for one or more aDSO’s)
2 – Select the time period and the action. Here you can move to warm and/or delete the partition. You can also have multiple steps for the rule (it’s worth noting that you cannot move data directly from Hot to Cold, you must go to warm as an interim step).
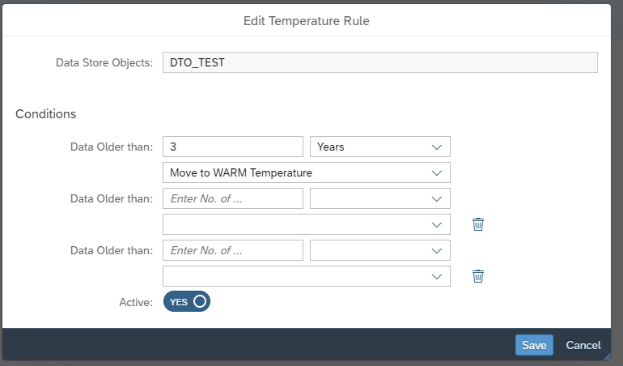
N.B. Defining the rule is client specific, and cannot be transported through the system landscape. All other aspects relating to DTO should be transported.
The system is now ready to execute the DTO rule and, as ever, this can be achieved in one of a few ways.
- Within the Manage Data Tiering Fiori Tile
- DTO Execution within the Administration Pane in RSA1
- Using the Adjust Data Tiering step in a process chain
Naturally, I’d recommend the use of setting up the process chain, which can be created without a rule being present.
An important point to mention is that if you are executing DTO on Data Mart type aDSO’s you must perform a Clean-Up Action of type ‘Activate Requests’ (‘Compress’ for the more experienced BW Consultants!) before the partitions will be considered for temperature maintenance.
Conclusions
Our system was initialised with ~5 years of data, and we had configured a number of our aDSO’s for DTO. Each had a rule to move anything older than 30 months into warm storage.
After a successful DTO execution we were able to see that the relevant partitions had been moved into warm storage as per the temperature rule definitions and we could also see the size of the memory in warm storage.

However, the Fiori Tile does offer a different picture – but I do not believe this view to be accurate so use this with caution.

I have been able to see from the DBA Cockpit that the partitions are marked as page loadable and stored on disk.
After we had executed the DTO job for all of our aDSO’s we were able to see the results (see below) of the total data that had been moved from hot to warm storage by using the standard Data Volume Statistics Fiori Tile.
Almost half of the data held in hot storage, which in this instance was ~30% of the total memory usage, had moved from hot to warm storage resulting in excess of 400gb of memory being freed up, overall, an impressive result from the starting position. The reduction in memory usage future proofs the system for significant organic growth or additional reporting datasets.
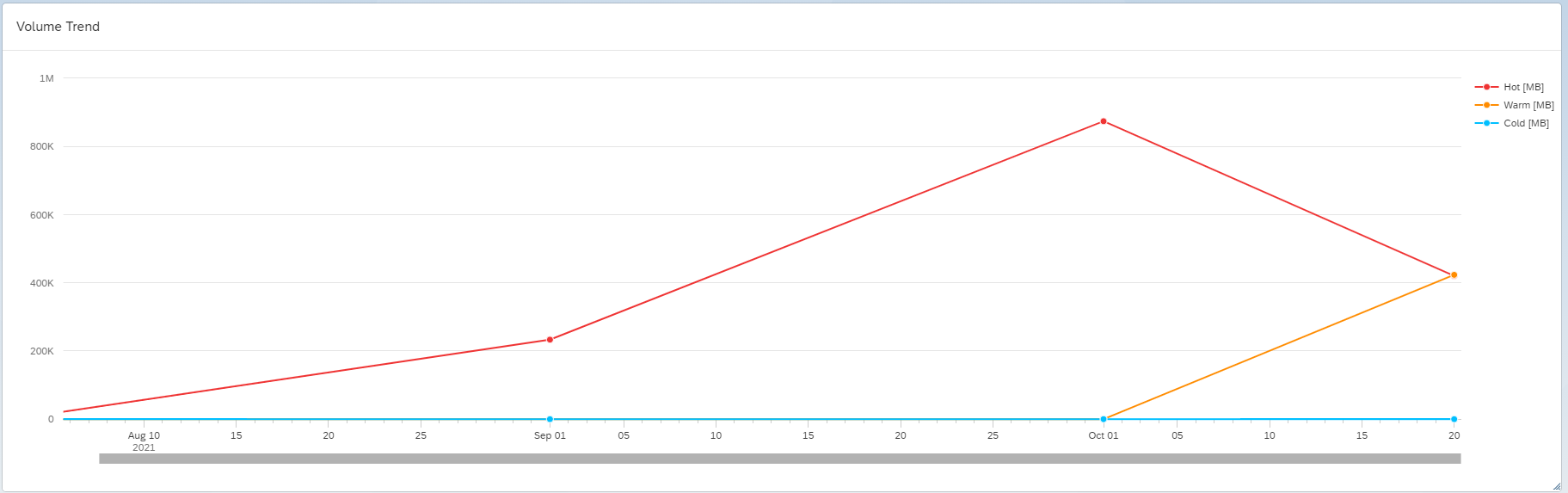
The impact on the growth of used disk space was negligible, if even noticeable.
We executed a number of queries to assess the query performance. The queries being used did have a single selection on 0FISCPER so we knew it would be hitting one page loadable partition, however, the composition of the query itself was made up of multiple calculated key figures and restricted key figures so there was still work to be done by the data manager.
We performed two executions (different Fiscal Year/Periods) of one query where the data was in hot storage and a further two on executions (again different Fiscal Year/Periods) of the same query where the data was in warm storage.
There was marginal difference, 0.6% slower, between the data being stored in hot and warm storage.
A second test on a more complex query returned similar results: a further test was executed here and that was to run the query with the same fiscal year / period twice for the data in warm storage, the result of that was zero time in the data manager. This proved that it had read from the memory cache. None of this is suggesting we will get the same performance across all queries but we were extremely impressed by the initial findings and will continue to advocate the use of NSE on future projects.
All of the Fiori Tiles referenced in this blog are available via the BW4 Web Cockpit.
If you’re interested in learning more or wish to discuss any of this technical content in more detail then please get in touch