SAP HANA Cloud Data Lake – Part 2

This blog serves as the latest instalment in this series of blogs covering SAP HANA Cloud.
In my first blog, I shared my initial impressions of SAP HANA Cloud and catalogued my adoption of the HDI development paradigm. This sets out the new tooling and capabilities of this platform.
In the follow-up blog, I made good on my promise to provide a similar appraisal of the Data Lake capabilities. This provided an appreciation of the architectural underpinning of SAP HANA Cloud Data Lake and define its relationship with SAP HANA Cloud. The blog steps through a scenario involving data loads from AWS S3 via the CLI.
The data juggernaut continues with this blog!
My last blog ran out of road, as I was unable to automate the mass load of files hosted on S3. Whilst I was able to load individual files (and multiple files) by explicitly listing them, this was impractical to load ~1700 unique CSV files. I concluded that the LOAD TABLE statement does not support a recursive load.
I must admit that I have been burning some midnight oil since then, to come up with a viable solution. Before I dive in, I do expect the ensuing sections to be technically oriented and it may be helpful to glance through the preceding blogs to establish the necessary context.
Here they are again:
In the remainder of this blog, I will step you through the solution I have developed, to support the mass load of files.
Firstly, I have a new Column Table in SAP HANA Cloud, which lists each file in S3 along with an accompanying integer serving as a unique identifier. I was able to retrieve a list of these files using the S3 CLI. This can be accessed via Windows Power Shell.
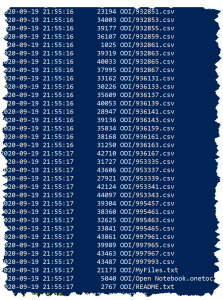
The CLI also supports a whole range of S3 administrative efforts e.g. moving files, renaming, etc. I strongly recommend the use of this CLI if you are looking to load a substantial amount of data/files.
The resultant DB Table is named “AM_LOAD_FILE” and here is a preview of this Table:
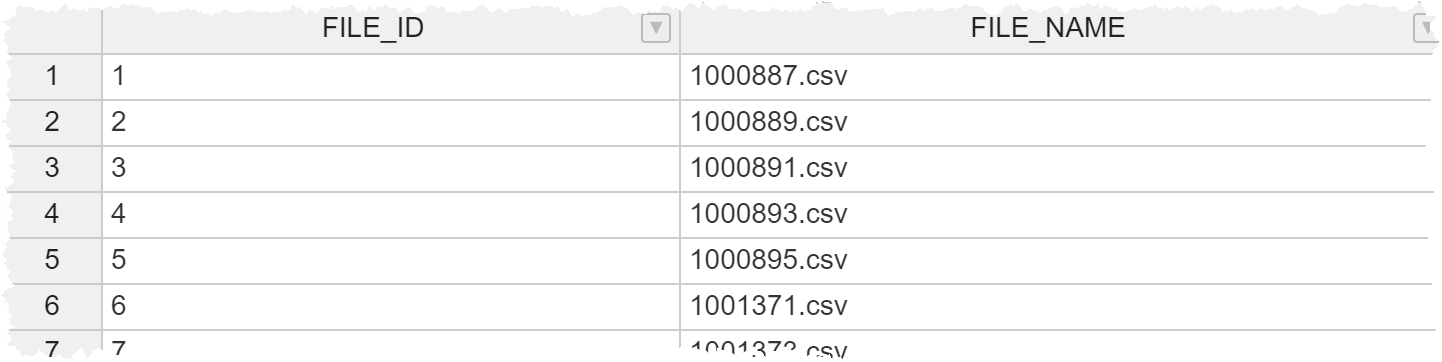
The above data will feed into the main Stored Procedure (SP) to determine the number of iterations based on how many files currently reside on S3 and secondly, provide the specific file name as part of each iteration. The file name is used to locate and process the file. I also store the file name to support error handling.
With the above in place, here is an overview of the entire SP:
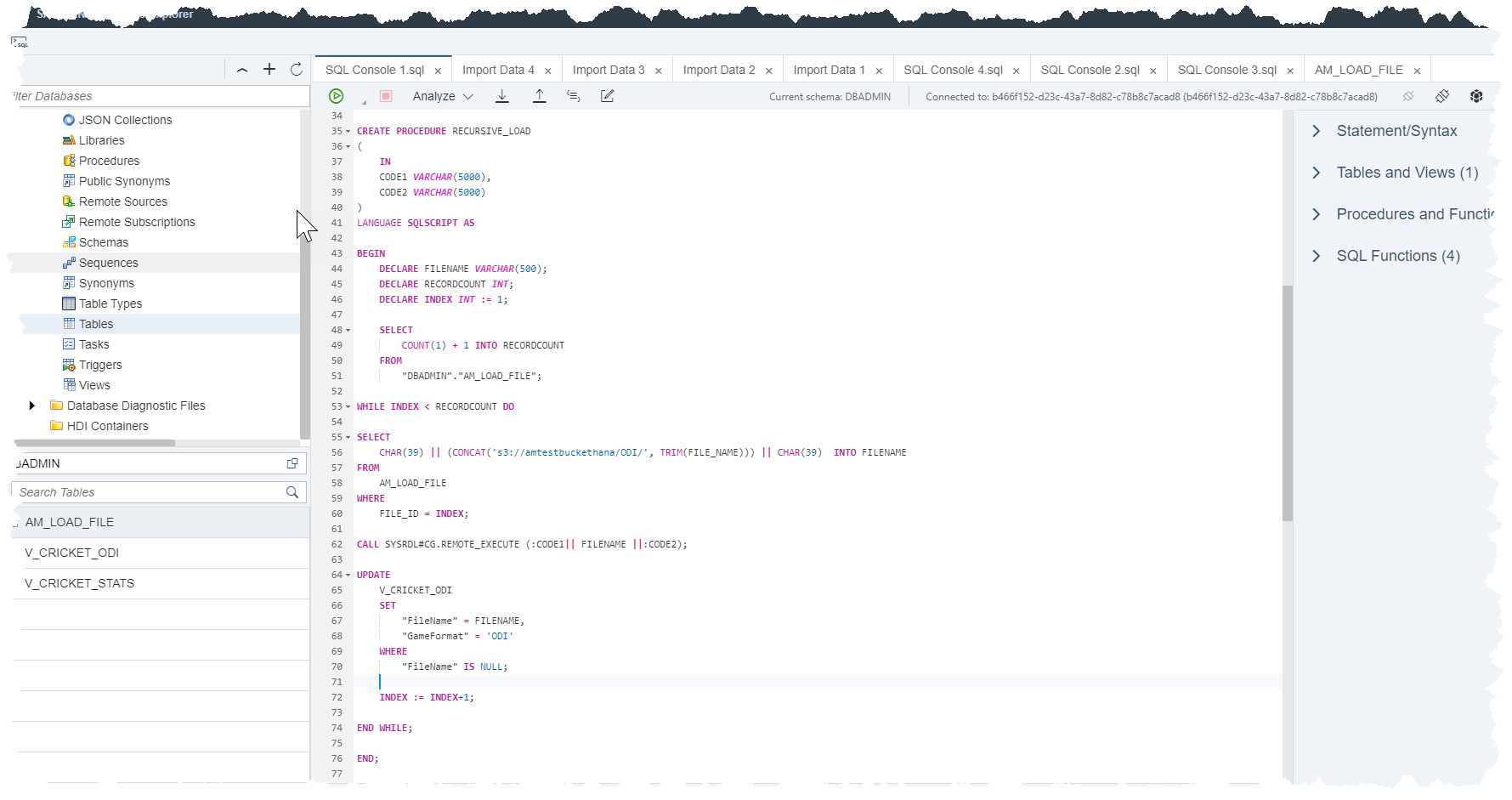
I will now break this down into the constituent parts and provide accompanying commentary. Firstly, there are two input parameters for this SP: The first part of the LOAD TABLE statement and the latter part of this statement. Both of these are static fragments of code and will be revealed shortly.
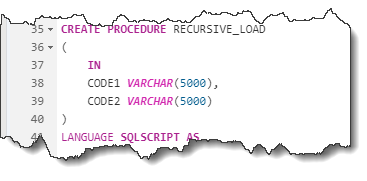
Importantly, the above parameters are surrounding the file name, which is passed in from the Table identified above. This takes me to the variables that feature in this SP:

The above code uses the Table holding the file names to set the value of INDEX. This is 1 more than the total number of records in this table i.e. files in S3. Note that the WHILE loop will continue until we have reached this number of iterations.
Now to the body of the LOOP statement:
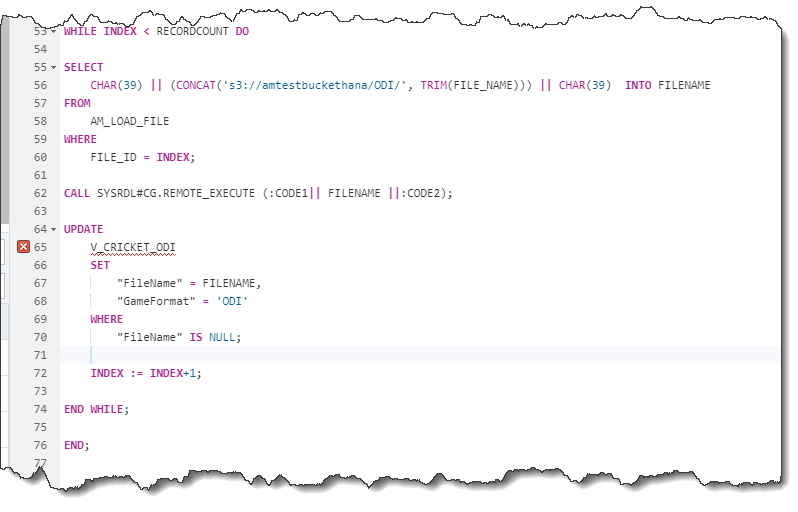
This takes each individual file name and prepends it with the S3 address (to form a fully qualified file name), accompanying quotes (CHAR(39)) and finally, the INDEX ensures that each file name is retrieved as part of the related iteration of this LOOP statement. The code is executed as part of the CALL statement and as mentioned above, this compiles the different portions of this statement. Finally, the UPDATE statement, commits the “FileName” into the underlying Table.
Once the SP has been compiled, we are ready to execute this using the following CALL statement:
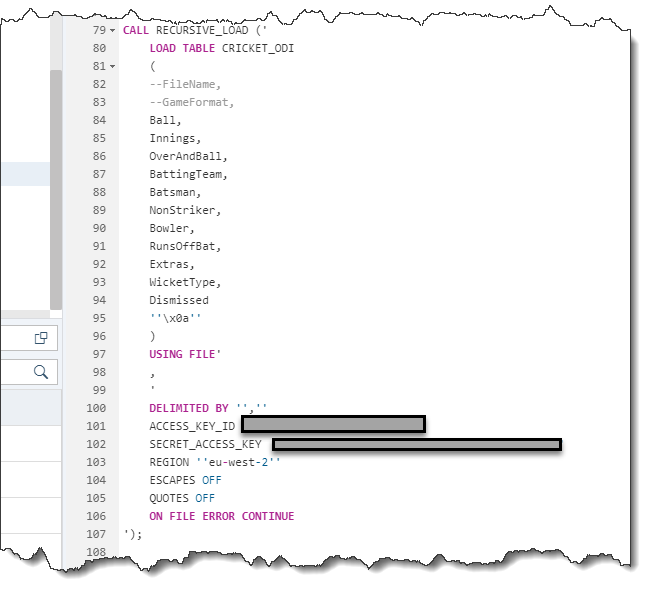
The above passes in the required parameters for this SP and as per earlier explanations, the file names are dynamically included as part of the SP logic.
Once the execution is complete, we can view the resultant data via the Virtual Table:
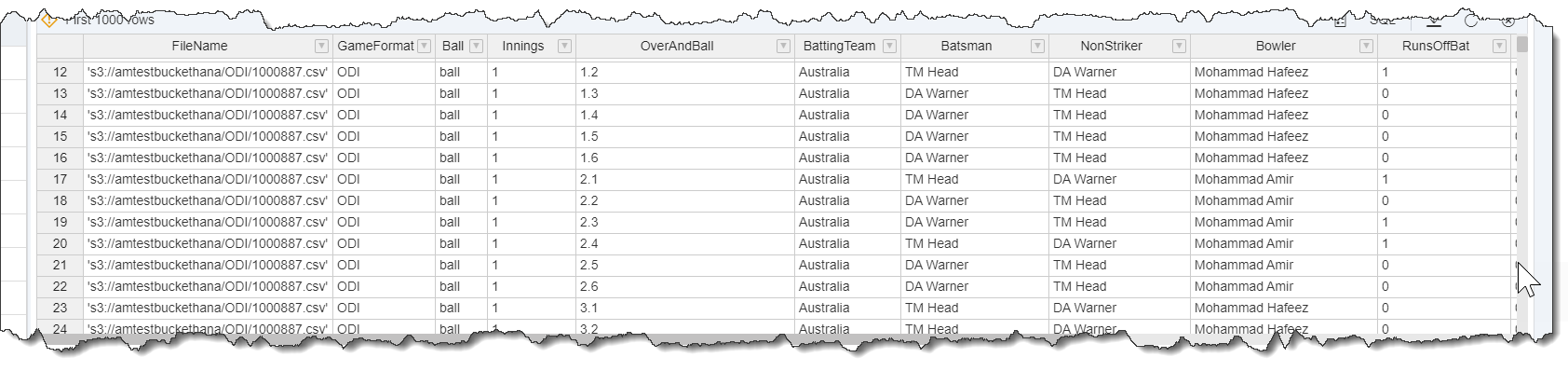
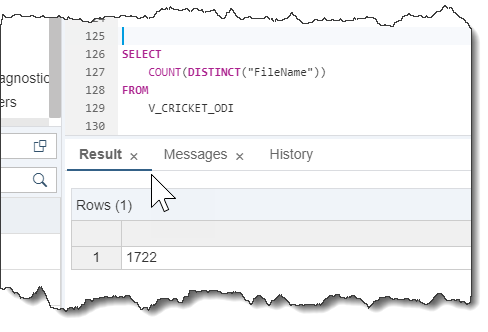
Some further validation of the results:
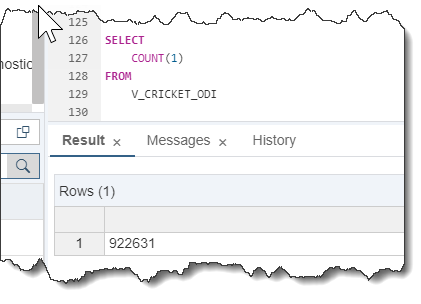
In addition, the unique matches/file…
I appreciate that there are a few moving parts to this and full marks for perseverance, if you have managed to get this far!
I hope you have been able to follow the images and associated explanations.
In summary, the LOAD TABLE statement is unable to cycle through a large number of files (~1700 in my example) residing in S3. To overcome this, I have developed the above code. Once executed, it will cycle through your S3 contents and load this into SAP HANA Cloud Data Lake – irrespective of how many files exist in a given situation.
In future blogs, I will leverage this data for analytical purposes. I will give some thought to the typical use cases whilst I am on (another!) staycation next week…
As always, please get in touch if there are any questions or insights that you wanted to share.