Im letzten Blogartikel wurde exemplarisch ein Anwendungsfall für datenbasierte Klassifikationen in einem Predictive Maintenance-Kontext vorgestellt, bei dem auf die Funktionalitäten der SAP HANA Predictive Analysis Library (PAL) in Form der Random Decision Trees zurückgegriffen wird.
Blogreihe: Risiken managen mit SAP Analytics Cloud und SAP HANA
SAP HANA Automated Predictive Library und Versicherungsbetrug (Teil 9)

Die mit dieser Bibliothek verbundenen Chancen sind umfangreich, jedoch bedarf es zu ihrem Einsatz zugleich eines sehr spezifischen Fachwissens. Geringere Hürden werden durch die Automated Predictive Library (APL) geschaffen, die zahlreiche automatisierte Funktionalitäten gekapselt zur Verfügung stellt. So sind beispielsweise prädiktive Services verfügbar, mit denen etwa Clustering-, Zeitreihen-, Statsbuilder- oder aber Regressions- sowie Klassifikations-Modelle erstellt werden können. Hierbei muss angegeben werden, welche dieser Möglichkeiten Anwendung finden soll, wie zum Beispiel die Klassifikation auf Basis zugrundeliegender Beobachtungen. Es zeigt sich dabei ein Unterschied zur genauen Benennung und Parametrisierung einer einzelnen Funktion einer Modellklasse. So wurde bei der Nutzung der PAL innerhalb der Klassifikationsklasse spezifisch auf die Random Decision Trees zugegriffen.
Insgesamt werden mit der APL aktuell die folgenden drei Bereiche angeboten:
- Predictive Model Services
Mit dieser Kategorie werden Funktionalitäten rund um prädiktive Modelle zugänglich.
- Predictive Business Services
Hier werden einfachere prädiktive Dienste auf höherer Ebene angeboten. Es sind besonders wenige Eingaben erforderlich.
- Technical Services
Zur Verfügung steht innerhalb dieser Kategorie die Abfrage nicht-prädiktiver, technischer Informationen wie beispielsweise die Beschreibung von APL-Schnittstellen.
Wie in unserer Serie schon mehrfach erwähnt, ist für das Risikomanagement insbesondere die vorausschauende Datenanalyse relevant. In diesem Kontext kann der Einsatz der APL gerade hinsichtlich Predictive Model Services erwogen werden. Denn ganze Aufgabenpfade können mit ihr bewältigt werden. Beginnend mit der initialen Erstellung eines sogenannten Analysemodells über das zugehörige Training bis hin zu seiner Anwendung und Testung werden zahlreiche Funktionalitäten bereitgestellt. Diese sind gerade auch zur Validierung erster (Proof of Concept-)Überlegungen einsetzbar. Die Bezeichnungen verschiedener vordefinierter Funktionen, die bezüglich des Zustands eines prädiktiven Modells einwirken beziehungsweise angewandt werden können, sind der folgenden Abbildung zu entnehmen. Vorteilig ist dabei, dass die Namen sprechend und damit verständlich gewählt sind. Hierdurch ergibt sich ein Überblick zu zentralen Funktionalitäten:
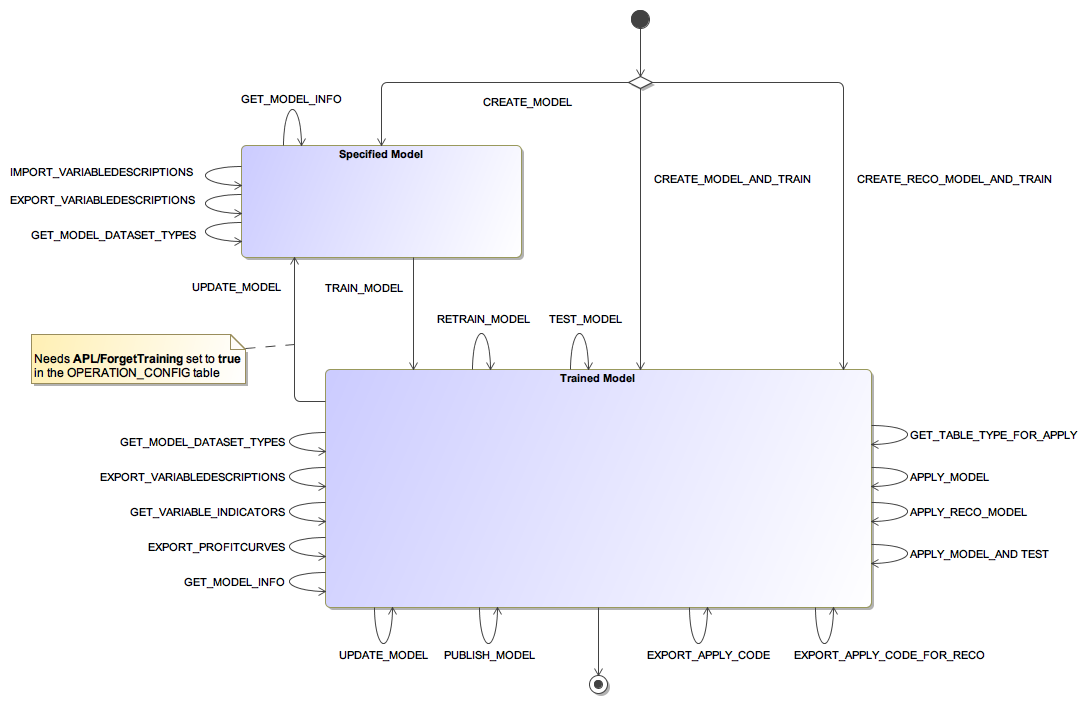
Abbildung 1: Überblick zu Funktionen des APL Predictive Services Modells, Quelle: SAP (2021)
Demgegenüber sind die Predictive Business Services in der Regel wesentlich einfacher strukturiert. So muss meist lediglich die Datengrundlage in Verbindung mit Konfigurationsparametern bereitgestellt werden. Nach Aufruf der jeweiligen Funktion erhält der Nutzer dann bereits finale Ergebnisse, ohne dass weitere Schritte nötig wären. Ein anschauliches Beispiel zur Anwendung der APL im Dienste der Vorhersage möglicher Fälle von Autoversicherungsbetrug findet sich unter diesem Link. Ein Auszug der zum Training herangezogenen Datengrundlage ist in Abbildung 2 ersichtlich:
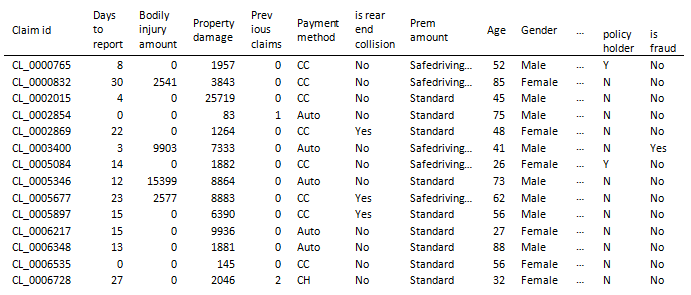
Abbildung 2: Past Claims Dataset, Quelle: SAP (2021)
Um auf Basis dieser vergangenheitsbezogenen Informationen Vorhersagen zu generieren, werden lediglich die mit den Ziffern 1 und 2 in der nachfolgenden Grafik markierten APL-Funktionen eingesetzt:
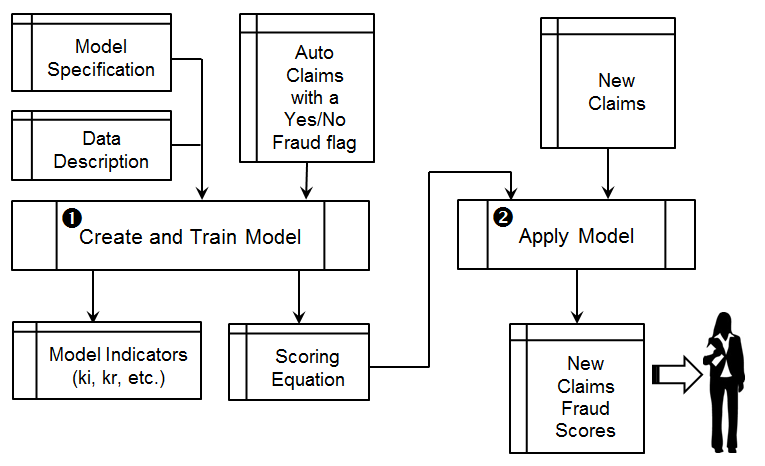
Abbildung 3: Lösungsskizze zur Vorhersage von Versicherungsbetrug, Quelle: SAP (2021)
Es ergeben sich hieraus Vorhersagen zu konkreten Anträgen, die auf mögliche Betrugsfälle («Fraudulent Claim») verweisen:
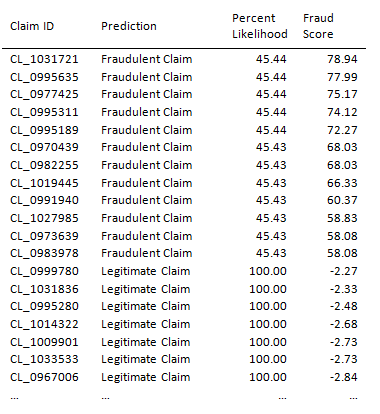
Abbildung 4: Vorhersageergebnisse (auszugsweise), Quelle: SAP (2021)
Zusammengefasst können verschiedene prädiktive Aufgaben an die APL delegiert werden, die ansonsten ausführlicher definiert und umgesetzt werden müssten. Allerdings ist dennoch zu prüfen, ob mit alternativen Verfahren ein überlegenes Ergebnis erzielt werden kann. Dies ist im Sinne einer Kosten-Nutzen-Analyse sicherlich auch unter dem Gesichtspunkt der Wartung zu entscheiden. Während die PAL primär den SAP Data Scientist anspricht, dürfte die APL eher für einen breiteren Anwenderkreis relevant sein. Trotz aller Erleichterungen ist oft dennoch eine Beratung hinsichtlich der Chancen und Limitationen der APL und ihrer Alternativen ratsam. Hierzu und auch zu allgemeinen Fragen stehe ich Ihnen gern zur Verfügung.
Jared Hirschner, SAP Data Scientist, NTT DATA Business Solutions
E-Mail: [email protected]
Ist hiervon etwas für Sie besonders interessant oder haben sich Fragen aufgetan?
Dann nehmen Sie gern Kontakt mit uns auf!
Blogreihe: Risiken managen mit SAP Analytics Cloud und SAP HANA

Teil 1 / 10
Risiken managen mit SAP Analytics Cloud und SAP HANA (Teil 1)
Teil 2 / 10
Zeitreihenprognose leicht gemacht – das Prognoseszenario der SAP Analytics Cloud (Teil 2)
Teil 3 / 10
SAP Analytics Cloud – Lineare Regression (Teil 3)
Teil 4 / 10
SAP Analytics Cloud – OnBoard-Methoden zur Zeitreihenvorhersage: Exponentielle Glättung (Teil 4)
Teil 5 / 10
SAP Analytics Cloud – OnBoard-Methoden zur Zeitreihenvorhersage: Automatische Prognose (Teil 5)
Teil 6 / 10
SAP Analytics Cloud – Potenzial heben mit der Programmiersprache R (Teil 6)
Teil 7 / 10
SAP HANA: Advanced Analytics und Machine Learning (Teil 7)
Teil 8 / 10
SAP HANA Predictive Analysis Library und SAP Analytics Cloud im präventiven Einsatz (Teil 8)
Teil 9 / 10
SAP HANA Automated Predictive Library und Versicherungsbetrug (Teil 9)
Teil 10 / 10
Ein Rück- und Ausblick (Teil 10)